数据驱动的机器学习提高水中生物炭对磺胺类抗生素吸附的预测
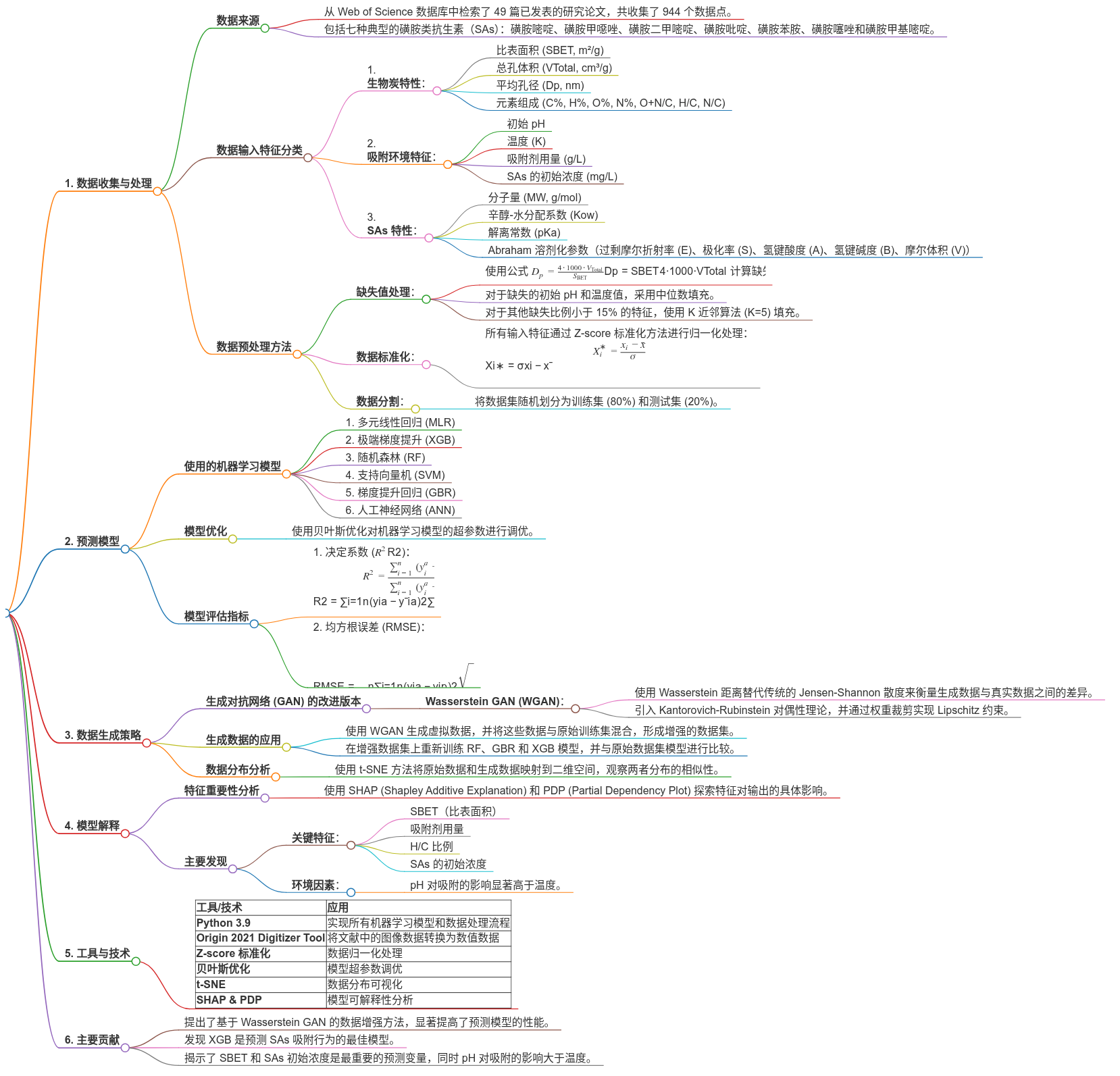
本论文题为《数据驱动的机器学习提高水中生物炭对磺胺类抗生素吸附的预测》,主要研究了利用数据驱动的机器学习方法,特别是基于 Wasserstein 生成对抗网络(WGAN)的数据增强方法,来预测磺胺类抗生素(SAs)在水中被生物炭(BCs)吸附的行为。研究通过文献收集了 944 个数据点,涉及七种典型的 SAs,并探讨了多种影响因素如 BCs 的物理化学性质、环境条件以及 SAs 的性质。通过对比六种常见的机器学习模型,发现极限梯度提升(XGB)模型在预测吸附量和吸附容量方面表现最佳。此外,研究还发现,通过 WGAN 生成的数据可以显著提高模型的预测性能。

论文的主旨:利用数据驱动的机器学习方法,特别是 WGAN 数据增强技术,来提高预测生物炭对磺胺类抗生素在水中的吸附行为的准确性。
论文的类别:环境科学与工程,具体涉及污染物吸附、机器学习和数据科学。
要解决的问题:目前缺乏系统性的机器学习模型来预测 SAs 在水中被 BCs 吸附的行为。
亮点:
创新性方法:首次将 WGAN 数据增强技术应用于预测 SAs 在水中被 BCs 吸附的行为。
模型优化:通过 WGAN 生成的高质量虚拟数据,显著提高了预测模型的性能。
关键因素分析:确定了影响吸附的关键因素,包括 BCs 的比表面积、初始 SAs 浓度以及环境因素如 pH。
论文框架:
引言:介绍 SAs 的环境风险、BCs 作为吸附剂的潜力以及机器学习在吸附研究中的应用。
材料与方法:详细描述数据收集、预处理、预测模型构建和数据生成策略。
结果与讨论:展示数据分析结果、模型预测性能、特征重要性分析以及特定因素对吸附的具体影响。
结论:总结研究的主要发现,包括最佳预测模型、WGAN 数据增强的有效性以及影响吸附的关键因素。
图文导读

图 1:收集数据的箱线图
- 目的:观察收集数据的分布特征。
- 展示:不同特征的数据范围和分布情况,如 BCs 的孔特征、元素含量等,以及环境特征中的 pH、温度等。
- 结论:不同特征的数据范围差异显著,部分数据存在偏态分布,需要进行标准化处理。

图 2:XGB 模型预测值与真实值的比较及残差分析图
- 目的:评估 XGB 模型对吸附量和吸附容量的预测性能。
- 展示:XGB 模型预测的吸附量和吸附容量与真实值的对比,以及残差分布情况。
- 结论:XGB 模型的预测值与真实值接近,残差接近零线且分布近似正态,表明 XGB 模型具有良好的预测能力。

图 3:WGAN 训练过程中的 Wasserstein 距离变化、t-SNE 可视化及增强数据集模型性能比较图
- 目的:展示 WGAN 训练过程中的性能变化,以及生成数据与原始数据的相似性,比较增强数据集模型与原始数据集模型的性能。
- 展示:WGAN 训练过程中 Wasserstein 距离随训练轮数的变化情况;通过 t-SNE 将原始数据和生成数据映射到二维空间进行可视化;增强数据集模型与原始数据集模型在预测吸附量和吸附容量上的性能比较。
- 结论:WGAN 训练过程中 Wasserstein 距离逐渐减小并趋于稳定,表明生成数据与原始数据的相似性增加;生成数据与原始数据在二维空间中的分布高度重叠,说明 WGAN 能够生成与原始数据高度相似的虚拟数据;增强数据集模型的预测性能显著优于原始数据集模型,表明 WGAN 基于的数据增强方法能够有效提升模型性能。

图 4:三个集成学习模型在不同数据集上的前 5 个特征重要性值
- 目的:分析不同模型在不同数据集上各特征对预测结果的重要性贡献。
- 展示:随机森林(RF)、XGBoost(XGB)和梯度提升回归(GBR)三个集成学习模型在“吸附”数据集、“pH”数据集和“温度”数据集上的前 5 个特征重要性值。
- 结论:在“吸附”数据集中,比表面积(SBET)、生物炭用量、氢碳比(H/C)和磺胺类抗生素初始浓度是预测吸附量和吸附容量的四个最重要的特征,其中 SBET 对预测的贡献最大;在“pH”和“温度”数据集中,pH 和温度特征的重要性相对较低,表明它们对吸附的影响较小。

图 5:XGB 模型中吸附容量预测的特征 SHAP 值及 pH 和温度的 SHAP 图
- 目的:深入分析各特征对吸附容量预测的具体影响。
- 展示:XGB 模型中吸附剂特征和环境特征对吸附容量预测的 SHAP 值;“pH”数据集中 pH 的 SHAP 图;“温度”数据集中温度的 SHAP 图。
- 结论:比表面积(SBET)和磺胺类抗生素初始浓度的 SHAP 值范围最大,且高值数据点的 SHAP 值集中在零轴右侧,表明它们对吸附容量有显著的正影响;生物炭用量对吸附容量有显著的负影响,随着用量的增加,吸附容量急剧下降;在“pH”数据集中,pH 在 2-6 范围内对吸附容量的 SHAP 值主要为正,在 6-10 范围内为负,表明 pH 对吸附的影响与溶液的酸碱性有关;温度对吸附容量的影响相对较小,其 SHAP 值范围在 -20 到 20 之间。
论文细节
1. 关键思路:解决数据驱动模型中的不足
论文的核心思想是通过生成对抗网络(GAN)的改进版——Wasserstein GAN(WGAN),生成虚拟数据来增强原始数据集,从而提高机器学习模型对生物炭吸附磺胺类抗生素的预测能力。论文指出,传统监督学习模型虽然能够实现一定效果,但通常受限于数据量或模型泛化能力不足。因此,作者创新性地引入了 WGAN,利用其高效的数据生成能力来弥补原始数据集的不足。
WGAN 的关键改进在于使用 Wasserstein 距离代替传统的 Jensen-Shannon 散度,解决了梯度消失和模式崩溃的问题。这使得生成的数据更加贴近真实分布,显著提高了模型的稳定性和预测性能。
2. 数据处理与特征工程
论文在数据收集和预处理方面投入了大量精力,确保输入特征的多样性和数据质量:
- 数据来源:从 49 篇文献中提取了 944 个数据点,涵盖多种磺胺类抗生素和生物炭的物理化学性质。
- 特征分类:将影响因素分为三类:
- 生物炭特性(如比表面积、孔径、元素组成等);
- 环境条件(如 pH、温度、初始浓度等);
- 磺胺类抗生素的分子性质(如分子量、溶解性参数等)。
- 数据清洗与标准化:采用 Z-score 标准化方法对特征进行归一化处理,避免不同量纲带来的偏差。同时,针对缺失值问题,使用 K 近邻算法(KNN)填补少量缺失数据,并用中位数填充极端情况下的缺失值。
特征工程的设计非常细致,充分考虑了吸附过程的多因素交互作用,为后续模型构建奠定了坚实基础。
3. 模型对比与选择
作者比较了六种常见的机器学习模型(MLR、SVM、RF、GBR、XGB、ANN)在原始数据上的表现,发现三种基于决策树的集成学习模型(RF、GBR、XGB)显著优于其他模型。最终,XGB 被选定为最佳预测模型,其测试集上的平均 R² 值分别达到 0.94 和 0.97,RMSE 值分别为 28.03 和 21.95,显示出极高的预测精度和稳定性。
此外,作者还对“pH”和“温度”两个子数据集进行了独立分析,发现不同模型的表现有所差异。例如,“温度”数据集较小且分布较分散,此时 GBR 的逐步优化机制使其更具优势。
4. WGAN 数据增强的效果
为了验证 WGAN 生成数据的有效性,作者将其应用于原始数据集的扩展,并评估了三种模型(RF、GBR、XGB)在增强数据集上的表现。结果表明:
- 在生成 200-600 个虚拟数据点时,模型的预测性能显著提升;
- 当生成数据点超过 800 个时,性能提升趋于饱和,说明模型已经学到了数据的主要分布特征。
通过 t-SNE 降维分析,作者证明了 WGAN 生成的数据在二维空间中与原始数据高度重叠,显示出生成数据的高相似性和代表性。
5. 特征重要性与具体影响分析
论文对模型的特征重要性进行了深入解析,揭示了以下几点关键结论:
- 主导特征:比表面积(SBET)和初始浓度是最主要的影响因素,SBET 在吸附量和吸附容量预测中的累积重要性分别达到 43.9%和 46.9%。
- 环境因素:pH 的影响大于温度,尤其是在 pH 2-6 范围内,吸附容量随 pH 增加而增大,但在 pH > 6 后迅速下降。
- 剂量效应:生物炭的投加量对吸附有显著负向影响,过多的投加会导致单位质量吸附效率降低。
通过 SHAP 值和部分依赖图(PDP)分析,作者进一步量化了各个特征的具体影响方向和强度。例如,较高的 SBET 和初始浓度会显著促进吸附,而过低或过高 pH 都会抑制吸附。
6. 创新点与意义
论文的创新点在于:
- 首次将 WGAN 应用于污染物吸附领域,成功生成高质量虚拟数据以增强模型泛化能力;
- 提供了一套系统性的方法论,从数据收集到模型构建再到特征分析,展示了如何利用机器学习技术解决复杂环境问题。
研究的实践意义包括:
- 帮助优化生物炭的制备工艺,设计高效的吸附材料;
- 为磺胺类抗生素污染治理提供理论指导;
- 推动机器学习技术在水处理领域的应用,助力可持续发展。
思维导图
总结
本论文通过结合数据驱动的机器学习方法和生成对抗网络技术(WGAN),提出了一个系统性的框架,用于预测生物炭对磺胺类抗生素在水中吸附的行为。作者首先通过大量文献收集构建了高质量数据集,并利用 Z-score 标准化和 KNN 填补策略处理缺失值。随后,对比了六种常见模型的性能,确定 XGB 为最优模型。在此基础上,作者采用 WGAN 生成虚拟数据进行数据增强,显著提高了模型的预测性能。最终,通过特征重要性分析和 SHAP 值解释,揭示了影响吸附行为的关键因素,如比表面积、初始浓度和 pH。论文不仅展示了方法论的创新性,还为实际应用提供了重要参考,推动了机器学习技术在环境科学领域的深度应用。