摘要
本文提出了基于密度泛函理论和机器学习技术的新型定量结构活性关系(QSAR)模型,该模型可用于预测异构过氧一硫酸盐(PMS)处理系统中的有机污染物氧化反应速率。这些预测工具有助于选择合适的处理系统,优化催化活性,增进我们对复杂AOP下污染物降解机制的理解。
贡献
- 建立使用密度泛函理论 (DFT) 和机器学习方法更新的QSAR模型,以预测异构PMS系统中一系列污染物的降解性能。
- 提供根据QSAR模型选择用于PMS处理特定污染物的最佳催化剂的策略。
实际意义
- 研究中开发的QSAR模型可用于预测异质PMS系统中一系列污染物的降解性能,这有助于选择合适的处理系统并优化催化活性。
- 这项工作增加了我们对复杂AOP下污染物降解机制的理解。
前言总结
本文的导言讨论了使用过氧一硫酸盐(PMS)作为去除环境污染物的有效氧化剂。它突出表明,经PMS处理会产生多种反应物质,从而触发不同的氧化途径,并且由不同活性物质诱导的各种降解机制主导。过渡金属钴已显示出活化PMS的潜力,使其成为有前途的催化剂选择。
使用的方法
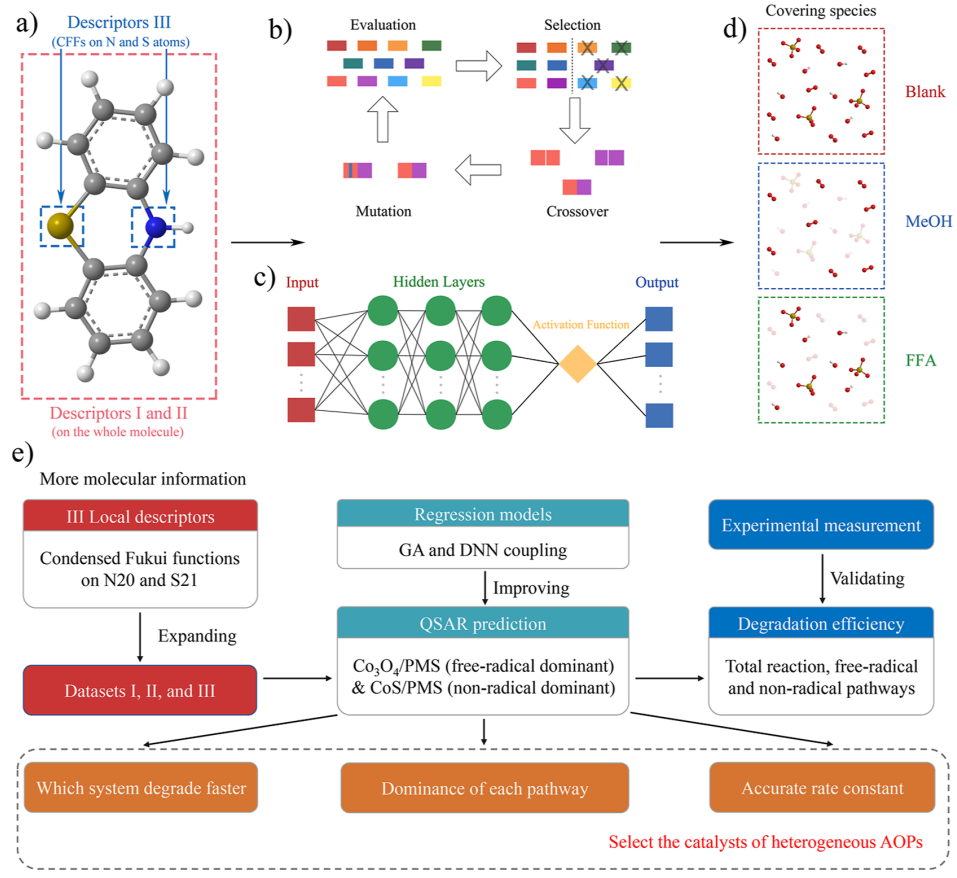
本文使用的方法包括建立定量结构活性关系(QSAR)模型,这些模型使用密度泛函理论和机器学习方法进行更新,以预测异质过氧一硫酸盐系统中一系列污染物的降解性能。使用受限 DFT 计算的有机分子特征作为输入描述符导入,而使用遗传算法和深度神经网络来提高预测准确性。这些 QSAR 模型可以作为有用的工具,用于根据污染物降解预测的定性和定量结果选择合适的处理系统,以及制定在 PMS 治疗期间选择最佳催化剂的策略。
使用的数据
本文中使用的数据包括使用约束密度泛函理论 (DFT) 作为输入描述符计算的有机分子的特性,以及作为输出的污染物的表观降解速率常数。使用机器学习方法更新 QSAR 模型,以提高预测准确性。
结果
该论文建立了使用密度泛函理论和机器学习方法更新的QSAR模型,以预测异质过氧一硫酸盐系统中一系列污染物的降解性能。结果表明,使用通过DFT方法获得的局部描述符作为输入数据集III增加了模型中包含的信息量,与MLR建模相结合可以提高预测精度。这些 QSAR 模型可以作为有用的工具,用于根据污染物降解预测的定性和定量结果选择合适的处理系统,以及制定在 PMS 处理期间选择最佳催化剂的策略。
结论
- 使用 DFT 和机器学习方法更新的 QSAR 模型可用于预测异构 PMS 系统中一系列污染物的降解性能
- 通过 DFT 方法获得的局部描述符被添加为数据集 III,这增加了输入数据集中包含的信息量。与 MLR 建模结合使用时,这显著提高了预测精度
- 根据使用这些 QSAR 模型的污染物降解预测得出的定性和定量结果,制定了在 PMS 处理期间选择最佳催化剂的策略。
局限性
- QSAR模型是基于有限数量的污染物和异质PMS系统开发的;因此,对其他类型的污染物或处理条件的适用性可能需要进一步验证。
- 尽管 DFT 以其预测分子特性的准确性而闻名,但将其应用于大分子或复杂的反应机制时,其计算成本也可能高昂且耗时。
- 尽管与多元线性回归 (MLR) 等传统统计方法相比,机器学习方法在提高预测性能方面显示出巨大希望,但它们仍然需要仔细选择和优化影响其可推广性的模型参数。
未来展望
- 通过整合更多样化和更全面的数据集,例如反应条件(例如,pH、温度)、催化剂特性(例如表面积、孔径分布)和水质参数,可以进一步改进 QSAR 模型。
- 应进行更多的实验研究,以验证这些QSAR模型在预测不同异质PMS处理系统下的降解性能方面的准确性。
- 需要进一步研究,探索其他先进的氧化过程,这些过程可能比基于过氧一硫酸盐的处理具有更好的效率或选择性。
你问我答
- 问:过氧化氢去除环境污染物的技术限制是什么,过氧化一硫酸盐(PMS)如何克服这些限制? 答:H2O2在去除环境污染物方面存在一些技术限制,例如在生成可以降解有机污染物的活性氧(ROS)方面,稳定性和选择性低。相比之下,过氧一硫酸盐(PMS)是一种比H2O2更稳定的氧化剂,它会产生多种具有不同氧化电位的活性氧来触发各种降解机制途径。事实证明,PMS处理系统可以有效去除水或土壤基质中的持久性或有毒污染物,因为它们在温和的反应条件下对各种类型的有机化合物具有很高的反应活性,而不会产生有害的副产物。
- 问:过渡金属,特别是钴,如何激活PMS产生不同的活性物质,以有效去除污染物? 答:钴等过渡金属可以激活过氧一硫酸盐(PMS),生成不同的活性物质,从而有效去除污染物。存在PMS的钴离子会发生氧化还原反应,生成高反应性中间体,包括硫酸自由基和羟基自由基,它们是强氧化剂,能够将有机污染物降解为无害产物。活化过程包括电子从Co (II) 转移到PMS形成中间复合物,然后对O-O键进行均质裂解,从而形成 SO4•− 自由基或 HSO5^•-离子,具体取决于 pH 条件。然后,这些活化物种通过各种途径与目标污染物发生反应,导致其降解。 据悉,这种活化背后的机制与钴等过渡金属离子能够充当路易斯酸并与存在于过氧二硫酸盐分子中的氧原子配位的能力有关,从而削弱过氧二硫酸盐分子中的氧键,使其在温和的条件下更容易分解,在芬顿试剂中,铁催化反应所需的恶劣酸性条件可能会导致不必要的副反应,从而在治疗过程中造成效率损失。
- 问:如何使用密度泛函理论(DFT)方法来获得分子信息,以了解QSAR模型中污染物的反应机制和环境行为? 答:密度泛函理论 (DFT) 是一种计算方法,用于计算分子的电子结构并预测其性质。在 QSAR 模型中,DFT 可用于获取分子信息,例如键长、角度、电荷或能量,这些信息与理解污染物的反应机制和环境行为有关。 通过将 DFT 方法与遗传算法或深度神经网络等机器学习算法相结合,可以开发出预测模型,这些模型能够根据从计算得出的有机化合物特性得出的输入描述符预测降解率,然后输出表观速率常数,使研究人员能够更好地了解不同因素如何影响不同条件下的污染物去除效率,包括 pH 值、温度等。 总体而言,这种方法为不同类别污染物的化学反应模式提供了宝贵的见解,从而能够制定更有效的处理策略,量身定制特定类型的废物流。
- 问:将深度神经网络(DNNs)与遗传算法相结合,对提高多变量非线性问题(如具有大量输入的QSAR模型)的拟合性能有何意义? 答:使用深度神经网络 (DNN) 和遗传算法来提高多变量非线性问题(例如 QSAR 模型)的拟合性能的重要性在于,它可以进行更准确的预测并更好地理解输入变量之间的复杂关系。 在传统的线性回归中,假设输入和输出之间的关系是一条直线,这可能并不总是正确的,尤其是在处理大型数据集或高度非线性的系统(例如环境污染物去除过程中发现的系统)时。 通过将 DNN 与遗传算法优化技术结合到 QSAR 建模中,研究人员可以开发出能够处理大量数据的预测模型,同时即使在涉及大量输入的条件下也能保持高精度水平,这使它们成为研究处理废水流过程中发生的复杂化学反应的理想工具
- 问:PMS处理系统中不同活性物质的污染物特性和降解效率之间的关系? 答:过氧一硫酸盐(PMS)处理环境污染物的效率取决于多种因素,包括存在的有机化合物的类型、其化学结构、附着在其上的官能团以及反应条件,例如pH值和温度。 经PMS处理过程中产生的不同活性氧物质具有不同的氧化电位,这决定了它们降解特定类型污染物的能力。例如,硫酸自由基在降解含有富电子芳香环或双键的化合物方面非常有效,而羟基自由基更容易与脂肪族链反应,因为它们对碳原子的亲电性更高。 因此,在使用钴等异构催化剂设计高效的催化过程时,了解这些各种氧化剂如何根据分子特性进行不同的相互作用非常重要。从环境上讲,多活性氧能够将复杂分子分解成更简单的分子,从而减少对环境的危害
文章思路
Materials and methods
- Catalyst Synthesis
- Descriptors
- Pseudo-First-Order k Values
- Regression Methods
Results and discussion
- Establishment of Free-Radical and Non-Radical Dominant Systems
- Contaminant Degradation and Descriptor Acquisition
- Development and Improvement of QSAR Models Using ML and DFT Approaches
- Selection of Optimal PMS Systems for Contaminant Degradation
- Environmental Implications
Personal interests
- MLR(Multiple Linear Regression):多元线性回归是指含有多个解释变量的线性回归模型,用于解释被解释变量与其他多个变量之间的线性关系。它可以用矩阵的形式表示为 y=X\beta+ \epsilon ,其中 y 是因变量向量,X 是设计矩阵,\beta 是参数向量,\epsilon 是误差向量。多元线性回归的目的是通过最小二乘法或极大似然法等方法估计参数 \beta ,并对方程和系数进行显著性检验和拟合优度分析。
- DNN(Deep Neural Networks):深度神经网络(DNN)是一种人工神经网络(ANN),它有一个输入层、一个输出层和多个隐藏层。它可以用于解决复杂的非线性问题,如图像识别、自然语言处理、语音识别等。 DNN的基本原理是利用前向传播算法和反向传播算法来训练模型的参数,使得损失函数最小化。前向传播算法是从输入层开始,逐层计算输出值,直到输出层。反向传播算法是从输出层开始,逐层计算梯度值,并更新参数。 DNN的优点是能够学习到深层次的特征表示,提高模型的泛化能力和准确性。DNN的缺点是需要大量的数据和计算资源,容易过拟合和陷入局部最优解。
- GA(Genetic Algorithm):遗传算法是一种计算数学中用于解决最优化问题的搜索算法,它模拟了自然界中的遗传、变异、选择和交叉等现象,从一个初始种群出发,通过不断地产生新的个体,使种群向更好的解进化。遗传算法有很多术语、过程和参数,需要根据具体问题进行设计和调节。 遗传算法有一些优点和缺点,根据不同的问题和应用场景,它们可能有不同的表现。我从网上找到了一些关于遗传算法优缺点的信息,你可以参考一下: 优点: 遗传算法具有良好的全局搜索能力,可以快速地将解空间中的全体解搜索出,而不会陷入局部最优解的快速下降陷阱。 遗传算法与问题领域无关切快速随机的搜索能力。 遗传算法利用它的内在并行性,可以方便地进行分布式计算,加快求解速度。 遗传算法仅考虑利用适应度函数获得的值,而不依赖于导数或任何其他信息。这使它们适合处理难以或不可能在数学上求导的函数。 遗传算法具有可扩展性,容易与其他算法结合。 缺点: 遗传算法的编程实现比较复杂,首先需要对问题进行编码,找到最优解之后还需要对问题进行解码。 遗传算法另外三个算子(选择、交叉和变异)的实现也有许多参数,如交叉率和变异率,并且这些参数的选择严重影响解的品质,而目前这些参数的选择大部分是依靠经验. 遗传算法没有能够及时利用网络(或环境)的反馈信息,故算法的搜索速度比较慢,要得要较精确的解需要较多的训练时间. 遗传算法对初始种群(或候选解集合)的选择有一定的依赖性,能够结合一些启发式(或其他)算法进行改进. 遗传算法必须已知适应度函数(或目标函数),这使得有很多较复杂的应用场景不太适合遗传算法建模。针对复杂问题,人为定义适应度函数是难以做到;不够科学(或准确) 的适应度函数又常常得不到效果理想.
- GA-DNN:GA-DNN是一种基于遗传算法(GA)和深度神经网络(DNN)的集成方案,用于解决一些复杂的问题,如单声道语音分离和金融科技指数预测。GA-DNN利用GA优化DNN的输入变量和超参数,然后利用DNN进行建模和预测。GA-DNN相比于单独使用DNN,可以提高效率和准确性。
- Descriptor:machine learning中的descriptor是一种用来表示分子结构的方法,它可以帮助机器学习模型预测分子的性质。通常,descriptor是一个数字、一个向量或一个矩阵,但也有可能是其他数据格式,比如字符串。
- Gaussian 16:Gaussian 16是一款用于电子结构建模的软件,它提供了最先进的计算化学功能。
- CFF(constrained Fukui functions):根据我的搜索结果,约束福井函数(constrained Fukui functions)是一种用于估计分子中最易发生电子转移的位置的化学描述符。福井函数(Fukui function)是概念密度泛函理论(Conceptual Density Functional Theory)框架下定义的非常流行的用于预测反应位点的方法。福井函数可以表示为电子密度(\rho ® )对电子数(N)的偏导数: f® = \frac{\partial \rho ®}{\partial N} 福井函数有两种有限表示形式,分别为 f^+® = \rho_{N+}® - \rho_N®和f^-® = \rho_N® - \rho_{N-}® 其中,f^+® 表示分子中原子的亲电性(electrophilicity),即受亲核攻击(nucleophilic attack)的倾向;而 f^-® 表示分子中原子的亲核性(nucleophilicity),即受亲电攻击(electrophilic attack)的倾向。